
The larger a project, the harder it is to test the code, and with most of the tests being functional – we have to face the problem: we finalize the task, the user story, or close the entire sprint and we have to wait for the tests for hours. This process can be vastly accelerated, even in legacy applications from the era of the PHP 4.
Above all, it is worth introducing unit tests into the new code – extract dependencies outside the code and test what is actually being developed. The tests are supposed to check our logical code, not the library or ORM. The introduction of unit tests is, however, a long-term step that does not give immediate results, which is why I’d like to show you what can be done on top of that.
Firstly, it must be said that one could write a book about the subject and still barely scratch the surface, so I’ll keep this article very brief and only touch upon the practical aspects based on my own experience – assuming a more difficult scenario, when the project has a lot of tests using the MySQL database.
PHP configuration
Do we need the xdebug extension every time we run the tests? It helps to measure the code coverage, but the test results do not depend on it, and its presence significantly extends the execution time of PHP code.
So, to verify that our modification or added functionality doesn't cause regression in the older code, we can run tests with xdebug disabled. When we need to measure how much code has been covered, we can turn it on, for example, via a switch in the PHP command line.
Another useful thing in the interpreter is the opcache module, used to store the compiled byte code of PHP files in the RAM. Proper configuration can significantly speed up the loading times of the application and test files by reducing the total time needed to recompile the source code.
When using opcache, it is worth remembering about the configuration for the development environment, which will allow you to validate files, for example, on time stamps in the file system, or keep comments (it is important for PhpUnit, because it uses annotations).
Example opcache configuration for the development environment:
The size of the value for max_accelerated_files can be measured using the commandfind
Multithreaded tests (includes database tests)
Despite numerous optimizations, our browser tests still take 8 hours, and functional test with unit tests take 2 hours. There is only one option left – split them into roughly same size groups and run them in parallel. Enough about PHP configuration, right? Now it gets interesting.
Architecture
Let me start with architecture. It is good to stack up on containers (a big project like this takes some serious tools, right?) The delivery to production servers is simplified with a little bit of automation.
The recently popular docker should come in handy. It is a good idea to put the application, i.e. php-fpm + possibly a webserver, in one or two separate containers, database into a separate container and do the same thing for selenium with vnc (and possibly cache, if using). For encouragement, I will add that the 12-year-old code with variable names in German and logic in templates also runs well in docker, so it seems no project is too old for it.
Example environment structure:
- application
- db
- selenium_chrome_vnc
- cache
Inserting the application into containers – especially in the context of tests – gives us the possibility of scaling the database, selenium and possibly the cache server (if we do not want to scale the container, we can e.g. prefix the keys instead).
By using environment variables, or scripts that generate configuration files, we can pass the name of the database instance to the application and, for example, manually test our code on two databases and run automated tests in parallel.
We assume that our application needs many containers to work, so it is worth using docker-compose, which allows you to manage the whole environment with configuration files.
Example file docker-compose.yml, containing the definition of two containers:
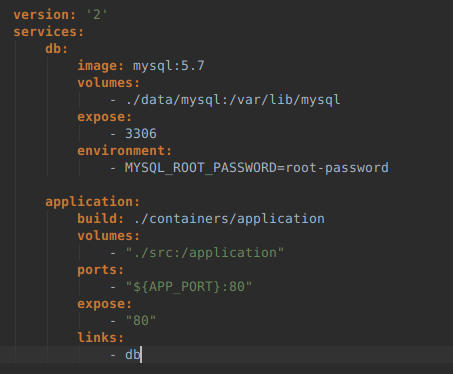
Compose allows to combine multiple containers, as well as use multiple configuration files that can be combined into one. A good example is the base configuration file docker-compose.yml for the production, and additionally the docker-compose.dev.yml that adds the development functionality, plus docker-compose.osx.yml with compatibility fixes for the development environment on OS X.
In addition, we also have the possibility to define environment variables in the .env file, which we add to .gitignore and create a template for it, e.g. env-template, from which each developer creates their own configuration file. Each developer can change the application port in the above example, thanks to which it will launch two applications in two environments on different ports.
If you feel overwhelmed by the amount of new commands to remember, I strongly recommend using the tried and tested Unix standard – Makefile. It allows you to define, in a way understandable for each developer, a set of commands to build a project and issue individual or linked commands like make pull build start:dev
Helpful tips:
Operation
Since we already have the architecture, we can restart containers, send commands to them using docker exec or docker-compose exec, and also scale them using e.g. docker-compose up -scale db=5.
How we actually will, for example, recreate the database for functional tests depends entirely on us. I will present the method I prefer.
First of all, docker gives the opportunity to create an image and copy it repeatedly. It also allows you to easily mount a directory to RAM, which significantly increases efficiency, e.g. in the case of a database access.
Let's use these two properties and build an image that will:
- Include a copy of our database.
- Include a script that will disable the database, then restore the backup and run the database again (in my case it takes 0.3 seconds at most).
- It will have a database installed in RAM (tmpfs) for faster read and write speeds
Assuming the script is called /rollback-database-from-backup.sh, you can use it to issue a simple command: sudo docker exec -i db_5_name /rollback-database-from-backup.sh – it will run the script for database instance number 5.
The script should wait for the database to roll back and then indicate that the procedure has been successful, logging the information to stdout.
In order to be able to execute such a command in the test environment, we may be tempted to create a very small API service, literally a “nano service" which will verify the input data and execute our script inside the launched container. I recommend Python and Tornado Framework – it can fit it all in 120 lines of code along with the initialization of the framework. Python is very similar to PHP, which allows easier understanding of the code by the rest of the developers in the team.
Running tests and collecting results
At the stage where the application is ready for parallel operation in one environment, we can start running multiple tests at the same time.
Below is an example of a script in bash, a prototype. Beginnings do not have to be big, final solutions.
In case the tests return errors, many things may be responsible – the database script may prematurely inform about readiness (milliseconds count), tests themselves may have dependencies between themselves, or any of the dependencies changing the state in the form of cache or another API service has not been wrapped in a container and scaled.
To properly handle database tests with implicit dependencies, we can mark them in a PhpDoc with a marker – such a marker can be easily extracted through Reflection. Another way is to implement the interface that enforces the implementation of the method responsible for informing how to prepare each test. However, it probably will not help if there are dependencies between tests in different files – such tests should be improved.
Assuming that we have put all the tests in good shape, they are running and passing – it is good to have a correct exit code from a multi-threaded script and distinguish which tests have been executed correctly by rewriting the script in Bash to Go, Python, or any other language that can process tests exit code, control several queues at once and control them.
It's basically everything. Let me try to summarize the above solution a bit.
Summary
Unquestionable advantages:
- A much faster test result, which is especially important when deciding whether you can finally release a new version of the application.
- The use of standards – the API allows easy access from the PHP test level and shell (you can set an alias in bash, for example to import/rebuild database).
- Infrastructure management via configuration files gives greater transparency regarding the infrastructure, at least parts of it
- The use of Makefile is clean, it gives additional validation to executed commands and the ability to combine several commands into chains, for example "make pull build start".
Disadvantages:
- Docker takes some getting used to. "It’s a fish out of water" I say every time when someone tries to run, for example, the Symfony console outside the working environment on the local shell, instead the docker container
- A larger project requires a bigger amount of RAM, up to 8 GB
- More infrastructure code to maintain
Automated tests increase the sense of safety of the team's work. Writing a test and making sure that others are working is a frequent point in the so-called "definition of done". Even an introduction of simple tests such as ‘is the controller returning proper values for given requests’ seems to be beneficial at start since it can quickly alert you about possible issues when something goes wrong.
When we run the pipeline at the end of the project’s sprint – it’s nice to have the results before 4pm.
